CLIP transformer#
Ths CLIP transformer was originally developed to classify images, with unknown classes at training time. On can use a pre-trained model for multiple classification tasks, by simply definint different classes at inference time.
This notebook is modified from example code here.
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
We first download a pre-trained model.
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open("data/real_cat.png")
image
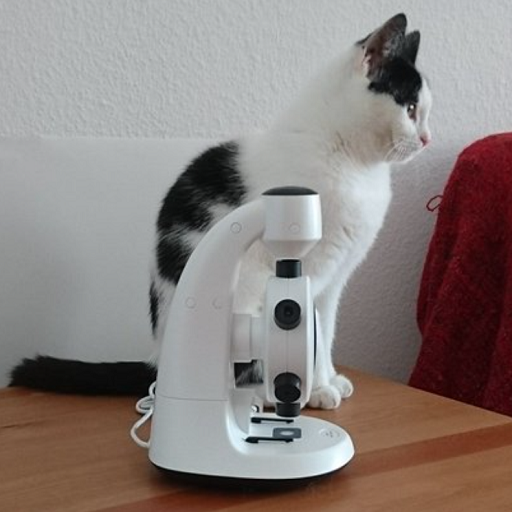
options = ["a photo of a cat",
"a photo of a dog",
"a photo of a microscope"]
#options = ["a photo of a cat",
# "a photo of a dog"]
inputs = processor(text=options, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
probs
tensor([[0.1353, 0.0013, 0.8634]], grad_fn=<SoftmaxBackward0>)
label_probabilities = {k: v for k, v in zip(options, probs[0].tolist())}
label_probabilities
{'a photo of a cat': 0.13529185950756073,
'a photo of a dog': 0.0012658964842557907,
'a photo of a microscope': 0.8634422421455383}